
Receptor models#
Quantitative pharmacologists construct models of relationship between ligand concentration and the fraction of cell surface receptors in each of several molecular conformations. These models give insight into the action of natural ligands and drugs on receptor-mediated cell responses.
The modeling process begings by specifying the molecular conformations (states) to be considered and the transitions between these states.
A three-state receptor model#
As a simple example, consider a receptor model with three states arranged as follows.
G = DiGraph({0: {1:'a01'}, 1: {0:'a10', 2:'a12'}, 2: {1:'a21'}})
pos = {0: (0, 0), 1: (1, 0), 2: (2, 0)}
G.plot(figsize=4,edge_labels=True,pos=pos,graph_border=True)

G = DiGraph({'R': {'RL':'kap*L'}, 'RL': {'R':'kam', 'RLL':'kbp*L'}, 'RLL': {'RL':'kbm'}})
pos = {'R': (0, 0), 'RL': (1, 0), 'RLL': (2, 0)}
G.plot(figsize=4,edge_labels=True,pos=pos,graph_border=True,vertex_size=1000)

When both forward and reverse transitions are explicit, the state-transition diagram has the topology of a symmetric directed version of the path graph with 3 vertices.
Here is the (undirected) path graph \(P_3\):
G = Graph({0: [1], 1: [2]})
G.plot(figsize=4)

The symmetric directed version is
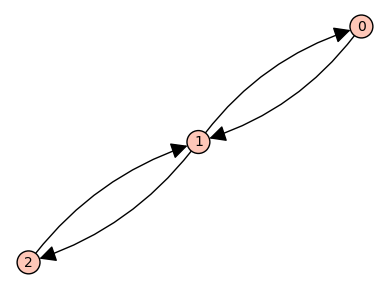
Our practice will be to define symbolic variables and put these on the vertices and edges.
var('a b c kappa_b_plus kappa_b_minus kappa_c_plus kappa_c_minus')
G = DiGraph([[a,b,c],[(a,b),(b,a),(b,c),(c,b)]])
G.set_edge_label(a,b,kappa_b_plus)
G.set_edge_label(b,a,kappa_b_minus)
G.set_edge_label(b,c,kappa_c_plus)
G.set_edge_label(c,b,kappa_c_minus)
G.plot(figsize=4,edge_labels=True)
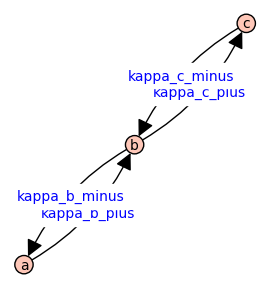
In the state-transition diagram shown above, \(\kappab\) and \(\kappac\) are dimensionless equilibrium constants, \(\kappabstar\) and \(\kappacstar\) are association constants with physical dimension of inverse concentration, and \(x\) is ligand concentration. The solid harpoons indicate the forward reaction direction. For example, the reaction labelled \(\kappab\) has \(a\) as reactant and \(b\) as product; consequently, increasing \(\kappab\) decreases the equilibrium probability (relative fraction) of state \(a\) and increases the probability of state \(b\). The three states of Equation XXX are labelled so that the reactant comes before the product in dictionary order (\(a\) to \(b\) to \(c\)). The subscript of the equilibrium constants \(\kappab\) and \(\kappac\) are chosen to match the label of the reaction products.
For an isolated monomer with a state-transition diagram given by Equation XXX, the probability of state \(i\) is given by \(\pi_i = z_i / z_T\) where \(z_T= \textstyle \sum_i z_i\), \(z_a = 1\), \(z_b = \kappab = \kappabstar x\), and \(z_c =\kappab \kappac = \kappabstar \kappacstar x^2\). That is,
It is helpful to present this set of rational functions using the following compact notation:
In expressions of this kind, it is understood that
for any \(\lambda \neq 0\). Furthermore, \(\lambda = 1/\sum_i x_n\) gives the probability distribution \(\pi = (\pi_1, \pi_2, \ldots, \pi_n)\) where \(1=\sum_i \pi_i\).
One reason for using symbolic variables is that we can produce symbolic expressions important quantities using module for graphs and digraphs available in Sagemath. For example, the weighted adjacency matrix associated with graph {math}`G$ above is
A = G.weighted_adjacency_matrix()
print(A)
[ 0 kappa_b_plus 0]
[kappa_b_minus 0 kappa_c_plus]
[ 0 kappa_c_minus 0]
If we are interested in the equilibrium probability of each state of the receptor model, it is sufficient to consider the rooted spanning tree
var('a b c kappa_b kappa_c')
T = DiGraph([[a,b,c],[(b,a),(c,b)]])
T.set_edge_label(b,a,kappa_b)
T.set_edge_label(c,b,kappa_c)
T.plot(figsize=4,edge_labels=True)
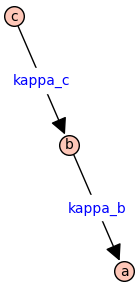
[To be completed]
Scraps#
B = T.weighted_adjacency_matrix()
print(B)
print(B**2)
print(B**3)
[ 0 0 0]
[kappa_b 0 0]
[ 0 kappa_c 0]
[ 0 0 0]
[ 0 0 0]
[kappa_b*kappa_c 0 0]
[0 0 0]
[0 0 0]
[0 0 0]
print(B)
print(B**2)
print(B**3)
[ 0 0 0]
[kappa_b 0 0]
[ 0 kappa_c 0]
[ 0 0 0]
[ 0 0 0]
[kappa_b*kappa_c 0 0]
[0 0 0]
[0 0 0]
[0 0 0]
G=graphs.PathGraph(3)
G.show(figsize=4)
G.relabel(dict({0: 'a', 1: 'b', 2: 'c'}))
G.show(figsize=4)
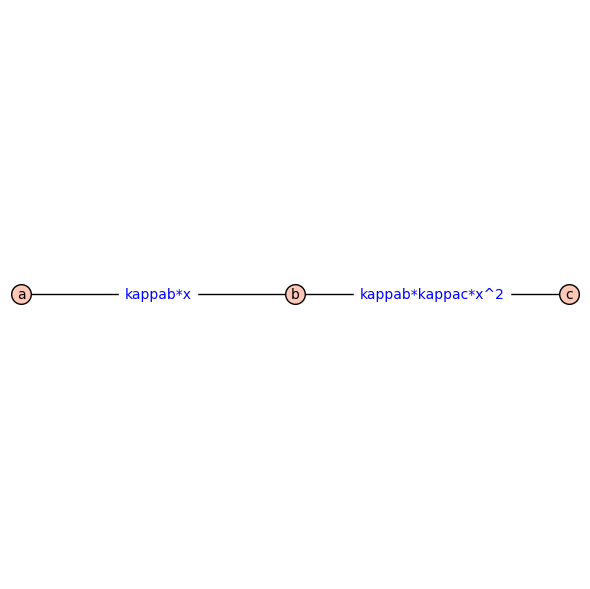
kappab = var("kappab", latex_name=r"\kappa_b")
kappac = var("kappac", latex_name=r"\kappa_c")
x = var("x", latex_name=r"x")
G.set_edge_label('a','b',kappab*x)
G.set_edge_label('b','c',kappab*kappac*x^2)
G.show(edge_labels=True,figsize=8)
f=kappab*kappac*x^2
f.show()
show(f)
print(f)
kappab*kappac*x^2
G=graphs.PathGraph(3).to_directed()
G.relabel({0:'R',1:'LR',2:'LLR'})
G.set_edge_label('R','LR','kap*L')
G.set_edge_label('LR','R','kam')
G.set_edge_label('LR','LLR','kbp*L')
G.set_edge_label('LLR','LR','kbm')
G.show(edge_labels=True,figsize=4,talk=True)
G.plot(edge_labels=True,figsize=4,talk=True)
