
Equilibrium formalism#
To illustrate the equilibrium formalism for receptor models, we will repeat our analysis of sequential binding using a standard notation. We begin with the weighted rooted spanning tree that specifies the equilibrium receptor model.
var('a b c kappa_b kappa_c')
T = DiGraph([[a,b,c],[(b,a),(c,b)]])
T.set_edge_label(b,a,kappa_b)
T.set_edge_label(c,b,kappa_c)
T.plot(figsize=6,pos={a:(0,0),b:(2,0),c:(4,0)},edge_labels=True,graph_border=True,vertex_size=1000)
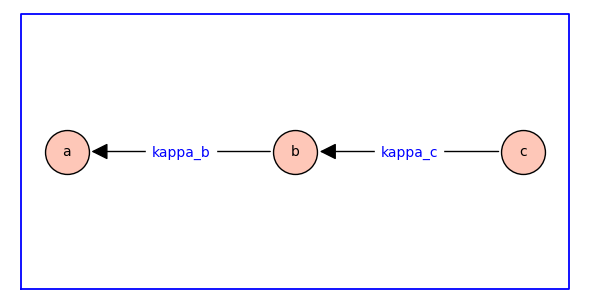
In the diagram above, \(\kappab\) and \(\kappac\) are dimensionless equilibrium constants.
The edges of the spanning tree are directed backwards, i.e., the forward reaction is against the direction of the arrow. For example, the reaction labelled with the equilibrium constant \(\kappab\) has \(a\) as reactant and \(b\) as product; consequently, increasing \(\kappab\) decreases the equilibrium probability (relative fraction) of state \(a\) and increases the probability of state \(b\).
The three states are labelled so that the reactant comes before the product in dictionary order (\(a\) to \(b\) to \(c\)). The subscript of the equilibrium constants \(\kappab\) and \(\kappac\) are chosen to match the label of the products.
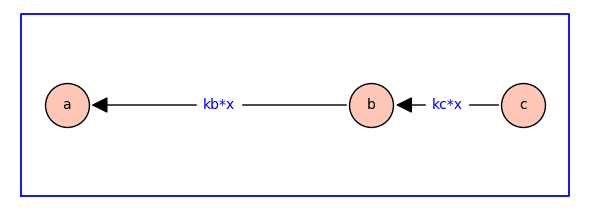
The dependence on ligand concentration is encorporated by defining \(\kappab = \kappabstar x\) and \(\kappac = \kappacstar x\) where \(\kappabstar\) and \(\kappacstar\) are association constants with physical dimension of inverse concentration, and \(x\) is ligand concentration.
var('a b c x kb kc')
T = DiGraph([[a,b,c],[(b,a),(c,b)]])
T.set_edge_label(b,a,kb*x)
T.set_edge_label(c,b,kc*x)
T.plot(figsize=6,pos={a:(0,0),b:(4,0),c:(6,0)},edge_labels=True,graph_border=True,vertex_size=1000)
Probability of each state#
For the equilibrium receptor model above, the probability of state \(i\) is given by \(\pi_i = z_i / z_T\) where \(z_T= \textstyle \sum_i z_i\), \(z_a = 1\), \(z_b = \kappab = \kappabstar x\), and \(z_c =\kappab \kappac = \kappabstar \kappacstar x^2\). That is,
It is helpful to present this set of rational functions using the following compact notation:
In expressions of this kind, it is understood that
for any \(\lambda \neq 0\). Furthermore, \(\lambda = 1/\sum_i x_n\) gives the probability distribution \(\pi = (\pi_1, \pi_2, \ldots, \pi_n)\) where \(1=\sum_i \pi_i\). Prior to normalization, we will refer to \([ z_1 \! : \! z_2 : \! \cdots \! : \! z_n ]\) as relative probabilites for each receptor state.
From spanning tree to relative probabilities#
By using a spanning tree as the specification for the receptor model, it is straightforward to extract symbolic expressions for the fraction of receptors in each state.
paths = T.all_simple_paths(starting_vertices=[a,b,c],ending_vertices=[a],trivial=True)
print(paths)
[[a], [b, a], [c, b, a]]
The list paths has length 3. paths[0]=[a]. paths[1]=[b,a]. paths[2]=[c,b,a]. These are vertices encountered in paths beginning at vertex 0 (a), 1 (b), and 2 (c) and (in each case) ending at vertex a.
The relative probability of each state is obtained as the product of the edge weights in each path, with the trivial path yielding 1 (an empty product).
z = []
for p in paths:
w = 1
for i in range(len(p)-1):
w = w*T.edge_label(p[i],p[i+1])
z.append(w)
print(z)
[1, kb*x, kb*kc*x^2]
The list z also has length 3. z[0] is 1. z[1]=kb*x. z[2]=kb*kc*x^2. These are the relative probabilities z_a, z_b, and z_c.
Symbolic expressions for the normalized probabilities are found as follows.
ztot = sum(z);
prob = []
for i in range(len(z)):
prob.append(z[i]/ztot)
print(prob)
[1/(kb*kc*x^2 + kb*x + 1), kb*x/(kb*kc*x^2 + kb*x + 1), kb*kc*x^2/(kb*kc*x^2 + kb*x + 1)]